
Category Archives: Machine Learning
Vector Quantisation: How Code Books Compress Similar Data
Vector quantisation replaces each group of values with the index of a representative vector. Learn how code books, k-means, distortion, and trade-offs fit together.

Exploring Lumiere: Google’s Astonishing Leap in AI-Driven Video Creativity
Hey there! Have you heard about Lumiere? If not, you’re in for a treat. Google’s latest marvel, Lumiere, is turning heads in the world of AI and video production. It’s not just another tech release; it’s a glimpse into a future where imagination meets reality, thanks to some seriously smart AI. Lumiere Unpacked: A Tech…

Revolutionising AI with Federated Learning: A New Era of Secure and Diverse Data Usage
Introduction: The landscape of artificial intelligence (AI) is evolving rapidly, and with it, the methodologies for training machine learning models. A pioneering approach that’s gaining traction is Federated Learning AI, a paradigm shift from the traditional centralized training methods. This article delves into federated learning, exploring its mechanics, types, challenges, and real-world implications. Unpacking Federated…

Building a Retrieval Augmented Generation (RAG) System: Harnessing AI for Enhanced Information Retrieval
Introduction In the realm of artificial intelligence and natural language processing, Retrieval Augmented Generation (RAG) systems stand as a beacon of innovation. These systems merge the meticulousness of retrieval-based AI with the creativity of generative models, creating a synergy that revolutionizes how machines understand and respond to human language. This blog post embarks on a…
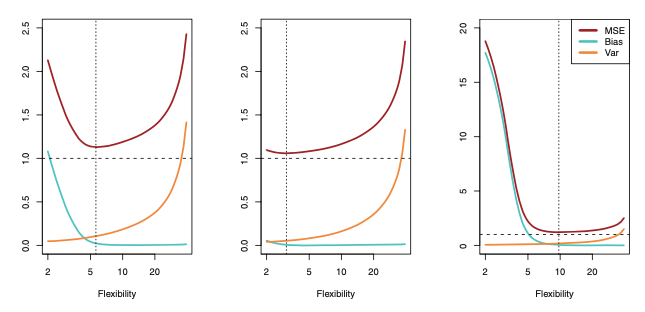
Relationship between bias, variance, and test set MSE
In all three cases, the variance increases and the bias decreases as the method’s flexibility increases. However, the flexibility level corresponding to the optimal test MSE differs considerably among the three data sets, because the squared bias and variance change at different rates in each of the data sets.

Balancing Act: Mastering Underfitting & Overfitting
Welcome to a journey through the delicate landscape of machine learning models! Today, we’re tackling two notorious pitfalls: underfitting and overfitting. Imagine you’re teaching a child to recognise animals. If you only show them pictures of small dogs, they might not recognise a large dog as a dog—that’s underfitting. The model is too simplistic and…
Difference Between Classification and Regression in Machine Learning
Classification vs Regression Classification predictive modeling problems are different from regression predictive modeling problems. Classification is the task of predicting a discrete class label. Regression is the task of predicting a continuous quantity.

What Are Ensemble Methods in Machine Learning?
Ensemble methods combine predictions from multiple machine-learning models to produce a more reliable result. Learn how bagging, boosting, stacking, and random forests work.
Entropy, Information gain, and Gini Index: Decision Tree
The decision tree algorithm is one of the widely used methods for inductive inference. It approximates discrete-valued target functions while being robust to noisy data and learns complex patterns in the data. The family of decision tree learning algorithms includes algorithms like ID3, CART, ASSISTANT, etc. They are supervised learning algorithms used for both, classification…