
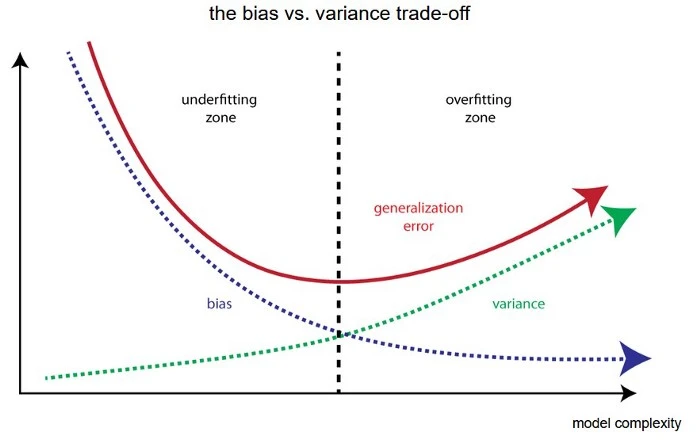
What is bias and variance in machine learning?
- Some models are too simplistic and ignore important relationships in the training data, which could have improved their predictions. Such models are said to have high bias. When a model has high bias, its predictions are consistently off, at least for certain regions of the data if not the whole range. For example, if you try to fit a line to a scatter plot where the data appears to follow a curve-linear pattern, then you can imagine that we won’t have a good fit. Some parts of the plot, the line will fall below the curve and other parts it will be above it, awkwardly trying to follow the trajectory of a curve. Since the line traces out the model’s predictions, then we can see that when the line falls below the curve, the predictions are consistently lower than the ground truth, and vice versa. So when you think of the word bias, think of predictions being consistently off. High-bias models are said to underfit [to the training data], and as such the prediction error is high both on the training data and test data.
- Some models are too complex, and the process of looking for important relationships between our variables, they also happen to pick up on certain relationships that turn out to just the result of noise. In other words, the model takes into account certain “flukes” in the training data that don’t generalize to the test data. In such a case, the model’s predictions are once again off, but here’s the important part: they are not consistently off. Change the data a little, and we can end up with very different predictions. Why? Because the model is too sensitive and over-reacting to the change in the data. High-variance models are said to overfit [to the training data], and as such their prediction error is deceptively low on the training data, but high on the test data, hence the lack of generalization.